
金融の世界は非常に広範で一般的に蔓延している病気に悩まされているため、「専門家」でさえ必要な深刻さでそれを受け入れていないようです。すぐに離脱の兆候が見られないこの病気は、「データマイニング」として知られています。これがインデックス構築にどのように影響するか、そしてなぜ注意する必要があるのかを示しています。これは、個人的な理由で匿名を希望する金融市場の専門家によるゲスト投稿です。
「Tech」のバックグラウンドを持つ読者の多くは、データマイニングについて常に前向きな意見を持っています。そのため、いくつかの分野で、データとデータマイニングは、顧客の行動を理解して売り上げを伸ばすという単純なものから、天気の傾向を分析するまで、驚異的に機能しています。予測する–データとデータマイニングはとても役に立ちました。ただし、財務および投資管理のコンテキストでは、「データマイニング」は問題です。
財務/投資管理のコンテキストで、データマイニングとは何ですか?データマイニングは、経済的で直感的な論理的根拠なしに過去のデータを調べることに他なりませんが、特に「優れた」パフォーマンスのパターンを探すことです。コンピューティング能力の向上と日中のデータの大規模な可用性を考えると、半ばまともなプログラマーが簡単なスクリプトを作成して、数百万とまではいかなくても数千のバックテストを作成して、優れた結果を出すことはそれほど難しくありません。ただし、専門家と投資家の両方が、投資の最も中心的な信条を都合よく忘れています。「過去は未来を示すものではありません」というこの声明は、投資信託の単一の株式またはユニットを購入したことのあるすべての人によって捨てられています。
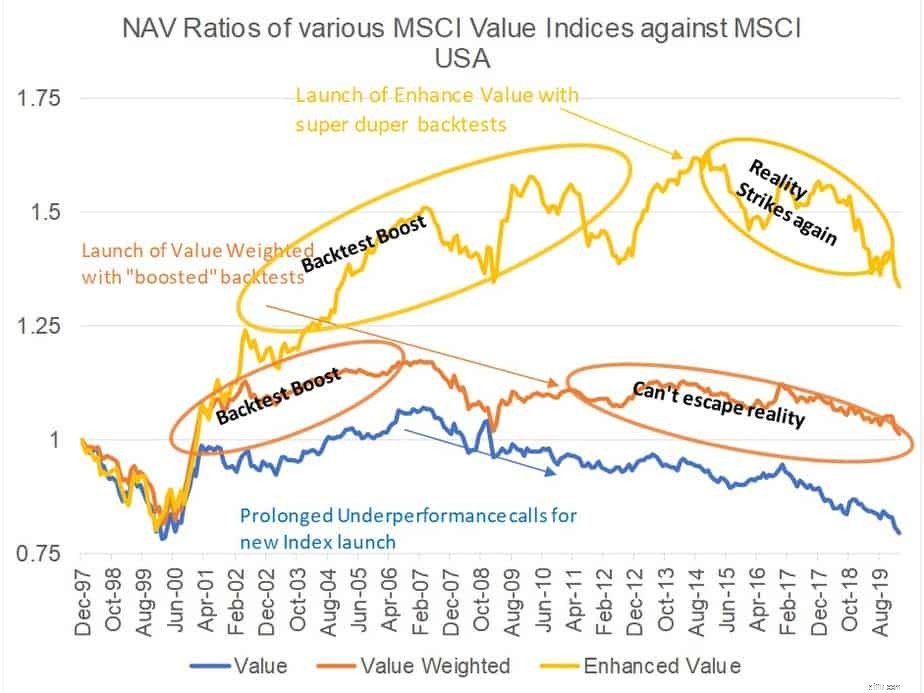
これは、実際のデータマイニングの図です。世界最大のインデックスプロバイダーであるMSCIは、インデックスを追跡するか、インデックスに対してベンチマークを行う数兆ドルのインデックスを持ち、MSCIバリューインデックス、MSCIバリュー加重インデックス、MSCI「エンハンスド」バリューインデックスの3つの異なる「バリュー」インデックスを持っています。論理的な人なら誰でも次の質問をするでしょう。同じプロバイダーから3つの異なる値のインデックスがあるのはなぜですか。どちらに投資すればよいですか?それらの違いは何ですか?どちらがもう一方よりも優れていますか?ファミリーの最古のメンバーであるMSCIバリューは、1997年以来稼働しており、バリュー加重インデックスは2010年12月に開始され、エンハンスドバリューは2015年4月に開始されました。 」。
次の図は、広範な市場指数に対する3つの価値指数すべてのNAV比率をプロットしたものです。知らない人のためのNAV比率は、あるインデックスNAVを別のインデックスNAVで割った比率です。比率の経済的解釈は、分子インデックス/ポートフォリオで「ロング」になり、分母インデックス/ポートフォリオで「ショート」になるロングショートポートフォリオのパフォーマンスです。したがって、NAV比率が上がると、分子インデックスは分母インデックス(この場合はベンチマーク)を上回り、下がると、分子インデックスは分母を下回ります。ご覧のとおり、特にバックテストでは、最新のインデックスが古いインデックスを大幅に上回っています。また、以前のインデックスのパフォーマンスが長期にわたって悪化した後、新しいインデックスが開始されるのを見るのは興味深いことです。 2 + 3 =5をまとめるのに、フォレンジックアナリストと調査ジャーナリストのチームは必要ありません。インデックスがリリースされて公開されると、インデックスはどうなりましたか?これはデータマイニングの結果です。データマイニングに悩まされている堅牢でないバックテストは、遅かれ早かれその本来の色を明らかにします。事実、学術的価値要因は10年以上にわたって成果を上げていません。データマイニングの量がその事実を変えることはできません。価値をどのように見ても、それを逃れることはできません。しかし、素晴らしい過去のパフォーマンスが売れています。男は食べなければならない、そして食べるために彼は売らなければならないので..!
データマイニングがあることをどうやって確信しているのか不思議に思うかもしれません。なぜ私たちは彼らに疑いの利益を与えることができないのですか?まあ、それは彼らの方法論文書で公開されています。以下は、MSCIがその要因を構築する際にいくつかの変数とそれらの重みを選択する方法に関する抜粋です。彼らは、バックテストでより良いリターン/ボラティリティを示した変数をオーバーウェイトしていることを露骨に認めています。これがデータマイニングの教科書の定義であり、彼らは公然と言っています–彼らはデータマイニングを行っています。それは2つのことのうちの1つだけを意味する可能性があります–1。彼らはデータマイニングをしていることすら知りません。 2.彼らは単に気にしません。 2つの理由のどちらが他より危険かわかりません。
これは、MSCIFaCS方法論ドキュメントの8ページのスクリーンショットです

わかりやすくするために、テキストを以下に複製します。
読者は、これは米国のデータ、米国の指数、米国のプロバイダーであると尋ねるでしょう。私は単にインドの投資信託に投資しているのですが、なぜ気にする必要があるのでしょうか。問題が、バックテストの実績、建設方法、発売日、ライブの実績が公開されているインデックスで露骨に蔓延している場合は、何にもアクセスできないお気に入りのアクティブファンドの規模と規模を想像してみてください。透明度はゼロです。インデックスはルールに基づいて体系的ですが、アクティブなミューチュアルファンドは完全に裁量です。投資信託業界でデータマイニングが普及する規模を理解することはできないでしょう。よろしくお願いします。SEBIは、各カテゴリの資金数を制限するルールを考案しました。
これは、私たちが何もバックテストしたり、バックテストのパフォーマンスを見たりしてはいけないということではありません。もちろん違います。過去のデータは、私たちが決定を下すために利用できる唯一の情報です。塩を少し入れてください。 Pattu卿が言うように、「チェリーが過去の最高のリターンを選ぶのは間違っています。チェリーピッキングの過去の最悪のリスクは慎重さです。」それだけです。データマイニングとは何か、そうでないものの1行の要約。それが、投資家としての私たちがリスクを理解するために、バックテストや過去のデータを一般的に扱う方法です。業界に関しては–希望はありません。


